

 Biblio
Biblio
Sophistication and flexibility of software development make it easy to leave security vulnerabilities in software applications for attack- ers. It is critical to educate and train software engineers to avoid in- troducing vulnerabilities in software applications in the first place such as adopting secure coding mechanisms and conducting secu- rity testing. A number of websites provide training grounds to train people’s hacking skills, which are highly related to security test- ing skills, and train people’s secure coding skills. However, there exists no interactive gaming platform for instilling gaming aspects into the education and training of secure coding. To address this issue, we propose to construct secure coding duels in Code Hunt, a high-impact serious gaming platform released by Microsoft Re- search. In Code Hunt, a coding duel consists of two code segments: a secret code segment and a player-visible code segment. To solve a coding duel, a player iteratively modifies the player-visible code segment to match the functional behaviors of the secret code seg- ment. During the duel-solving process, the player is given clues as a set of automatically generated test cases to characterize sample functional behaviors of the secret code segment. The game aspect in Code Hunt is to recognize a pattern from the test cases, and to re-engineer the player-visible code segment to exhibit the expected behaviors. Secure coding duels proposed in this work are coding duels that are carefully designed to train players’ secure coding skills, such as sufficient input validation and access control.
In real world domains, from healthcare to power to finance, we deploy computer systems intended to streamline and im- prove the activities of human agents in the corresponding non-cyber worlds. However, talking to actual users (instead of just computer security experts) reveals endemic circum- vention of the computer-embedded rules. Good-intentioned users, trying to get their jobs done, systematically work around security and other controls embedded in their IT systems.
This poster reports on our work compiling a large corpus of such incidents and developing a model based on semi- otic triads to examine security circumvention. This model suggests that mismorphisms—mappings that fail to preserve structure—lie at the heart of circumvention scenarios; dif- ferential perceptions and needs explain users’ actions. We support this claim with empirical data from the corpus.
Agent-based modeling can serve as a valuable asset to security personnel who wish to better understand the security landscape within their organization, especially as it relates to user behavior and circumvention. In this paper, we ar- gue in favor of cognitive behavioral agent-based modeling for usable security, report on our work on developing an agent- based model for a password management scenario, perform a sensitivity analysis, which provides us with valuable insights into improving security (e.g., an organization that wishes to suppress one form of circumvention may want to endorse another), and provide directions for future work.
In real world domains, from healthcare to power to finance, we deploy computer systems intended to streamline and improve the activities of human agents in the corresponding non-cyber worlds. However, talking to actual users (instead of just computer security experts) reveals endemic circumvention of the computer-embedded rules. Good-intentioned users, trying to get their jobs done, systematically work around security and other controls embedded in their IT systems.
This paper reports on our work compiling a large corpus of such incidents and developing a model based on semiotic triads to examine security circumvention. This model suggests that mismorphisms— mappings that fail to preserve structure—lie at the heart of circumvention scenarios; differential percep- tions and needs explain users’ actions. We support this claim with empirical data from the corpus.
Many current VM monitoring approaches require guest OS modifications and are also unable to perform application level monitoring, reducing their value in a cloud setting. This paper introduces hprobes, a framework that allows one to dynamically monitor applications and operating systems inside a VM. The hprobe framework does not require any changes to the guest OS, which avoids the tight coupling of monitoring with its target. Furthermore, the monitors can be customized and enabled/disabled while the VM is running. To demonstrate the usefulness of this framework, we present three sample detectors: an emergency detector for a security vulnerability, an application watchdog, and an infinite-loop detector. We test our detectors on real applications and demonstrate that those detectors achieve an acceptable level of performance overhead with a high degree of flexibility.
This paper presents the architecture of an end-to-end secu- rity testbed and security analytics framework, which aims to: i) understand real-world exploitation of known security vulnerabilities and ii) preemptively detect multi-stage at- tacks, i.e., before the system misuse. With the increasing number of security vulnerabilities, it is necessary for secu- rity researchers and practitioners to understand: i) system and network behaviors under attacks and ii) potential ef- fects of attacks to the target infrastructure. To safely em- ulate and instrument exploits of known vulnerabilities, we use virtualization techniques to isolate attacks in contain- ers, e.g., Linux-based containers or Virtual Machines, and to deploy monitors, e.g., kernel probes or network packet captures, across a system and network stack. To infer the evolution of attack stages from monitoring data, we use a probabilistic graphical model, namely AttackTagger, that represents learned knowledge of simulated attacks in our se- curity testbed and real-world attacks. Experiments are be- ing run on a real-world deployment of the framework at the National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign.
Hypervisor activity is designed to be hidden from guest Virtual Machines (VM) as well as external observers. In this paper, we demonstrate that this does not always occur. We present a method by which an external observer can learn sensitive information about hypervisor internals, such as VM scheduling or hypervisor-level monitoring schemes, by observing a VM. We refer to this capability as Hypervisor Introspection (HI).
HI can be viewed as the inverse process of the well-known Virtual Machine Introspection (VMI) technique. VMI is a technique to extract VMs’ internal state from the hypervi- sor, facilitating the implementation of reliability and security monitors[1]. Conversely, HI is a technique that allows VMs to autonomously extract hypervisor information. This capability enables a wide range of attacks, for example, learning a hypervisor’s properties (version, configuration, etc.), defeating hypervisor-level monitoring systems, and compromising the confidentiality of co-resident VMs. This paper focuses on the discovery of a channel to implement HI, and then leveraging that channel for a novel attack against traditional VMI.
In order to perform HI, there must be a method of extracting information from the hypervisor. Since this information is intentionally hidden from a VM, we make use of a side channel. When the hypervisor checks a VM using VMI, VM execution (e.g. network communication between a VM and a remote system) must pause. Therefore, information regarding the hypervisor’s activity can be leaked through this suspension of execution. We call this side channel the VM suspend side channel, illustrated in Fig. 1. As a proof of concept, this paper presents how correlating the results of in-VM micro- benchmarking and out-of-VM reference monitoring can be used to determine when hypervisor-level monitoring tools are vulnerable to attacks.
This paper presents a solution that simultaneously addresses both reliability and security (RnS) in a monitoring framework. We identify the commonalities between reliability and security to guide the design of HyperTap, a hypervisor-level framework that efficiently supports both types of monitoring in virtualization environments. In HyperTap, the logging of system events and states is common across monitors and constitutes the core of the framework. The audit phase of each monitor is implemented and operated independently. In addition, HyperTap relies on hardware invariants to provide a strongly isolated root of trust. HyperTap uses active monitoring, which can be adapted to enforce a wide spectrum of RnS policies. We validate Hy- perTap by introducing three example monitors: Guest OS Hang Detection (GOSHD), Hidden RootKit Detection (HRKD), and Privilege Escalation Detection (PED). Our experiments with fault injection and real rootkits/exploits demonstrate that HyperTap provides robust monitoring with low performance overhead.
Winner of the William C. Carter Award for Best Paper based on PhD work and Best Paper Award voted by conference participants.
Reliability and security tend to be treated separately because they appear orthogonal: reliability focuses on accidental failures, security on intentional attacks. Because of the apparent dissimilarity between the two, tools to detect and recover from different classes of failures and attacks are usually designed and implemented differently. So, integrating support for reliability and security in a single framework is a significant challenge.
Here, we discuss how to address this challenge in the context of cloud computing, for which reliability and security are growing concerns. Because cloud deployments usually consist of commodity hardware and software, efficient monitoring is key to achieving resiliency. Although reliability and security monitoring might use different types of analytics, the same sensing infrastructure can provide inputs to monitoring modules.
We split monitoring into two phases: logging and auditing. Logging captures data or events; it constitutes the framework’s core and is common to all monitors. Auditing analyzes data or events; it’s implemented and operated independently by each monitor. To support a range of auditing policies, logging must capture a complete view, including both actions and states of target systems. It must also provide useful, trustworthy information regarding the captured view.
We applied these principles when designing HyperTap, a hypervisor-level monitoring framework for virtual machines (VMs). Unlike most VM-monitoring techniques, HyperTap employs hardware architectural invariants (hardware invariants, for short) to establish the root of trust for logging. Hardware invariants are properties defined and enforced by a hardware platform (for example, the x86 instruction set architecture). Additionally, HyperTap supports continuous, event-driven VM monitoring, which enables both capturing the system state and responding rapidly to actions of interest.
Design-time analysis and verification of distributed real-time embedded systems necessitates the modeling of the time-varying performance of the network and comparing that to application requirements. Earlier work has shown how to build a system network model that abstracted away the network's physical medium and protocols which govern its access and multiplexing. In this work we show how to apply a network medium channel access protocol, such as Time-Division Multiple Access (TDMA), to our network analysis methods and use the results to show that the abstracted model without the explicit model of the protocol is valid.
Assuring communication integrity is a central problem in security. However, overhead costs associated with cryptographic primitives used towards this end introduce significant practical implementation challenges for resource-bounded systems, such as cyber-physical systems. For example, many control systems are built on legacy components which are computationally limited but have strict timing constraints. If integrity protection is a binary decision, it may simply be infeasible to introduce into such systems; without it, however, an adversary can forge malicious messages, which can cause signi cant physical or financial harm. We propose a formal game-theoretic framework for optimal stochastic message authentication, providing provable integrity guarantees for resource-bounded systems based on an existing MAC scheme. We use our framework to investigate attacker deterrence, as well as optimal design of stochastic message authentication schemes when deterrence is impossible. Finally, we provide experimental results on the computational performance of our framework in practice.
Cheap ubiquitous computing enables the collectionof massive amounts of personal data in a wide variety of domains.Many organizations aim to share such data while obscuring fea-tures that could disclose identities or other sensitive information.Much of the data now collected exhibits weak structure (e.g.,natural language text) and machine learning approaches havebeen developed to identify and remove sensitive entities in suchdata. Learning-based approaches are never perfect and relyingupon them to sanitize data can leak sensitive information as aconsequence. However, a small amount of risk is permissiblein practice, and, thus, our goal is to balance the value ofdata published and the risk of an adversary discovering leakedsensitive information. We model data sanitization as a gamebetween 1) a publisher who chooses a set of classifiers to applyto data and publishes only instances predicted to be non-sensitiveand 2) an attacker who combines machine learning and manualinspection to uncover leaked sensitive entities (e.g., personal names). We introduce an iterative greedy algorithm for thepublisher that provably executes no more than a linear numberof iterations, and ensures a low utility for a resource-limitedadversary. Moreover, using several real world natural languagecorpora, we illustrate that our greedy algorithm leaves virtuallyno automatically identifiable sensitive instances for a state-of-the-art learning algorithm, while sharing over 93% of the original data, and completes after at most 5 iterations.
Starting with the seminal work by Kempe et al., a broad variety of problems, such as targeted marketing and the spread of viruses and malware, have been modeled as selecting
a subset of nodes to maximize diffusion through a network. In
cyber-security applications, however, a key consideration largely ignored in this literature is stealth. In particular, an attacker often has a specific target in mind, but succeeds only if the target is reached (e.g., by malware) before the malicious payload is detected and corresponding countermeasures deployed. The dual side of this problem is deployment of a limited number of monitoring units, such as cyber-forensics specialists, so as to limit the likelihood of such targeted and stealthy diffusion processes reaching their intended targets. We investigate the problem of optimal monitoring of targeted stealthy diffusion processes, and show that a number of natural variants of this problem are NP-hard to approximate. On the positive side, we show that if stealthy diffusion starts from randomly selected nodes, the defender’s objective is submodular, and a fast greedy algorithm has provable approximation guarantees. In addition, we present approximation algorithms for the setting in which an attacker optimally responds to the placement of monitoring nodes by adaptively selecting the starting nodes for the diffusion process. Our experimental results show that the proposed algorithms are highly effective and scalable.
The quantity of personal data gathered by service providers via our daily activities continues to grow at a rapid pace. The sharing, and the subsequent analysis of, such data can support a wide range of activities, but concerns around privacy often prompt an organization to transform the data to meet certain protection models (e.g., k-anonymity or E-differential privacy). These models, however, are based on simplistic adversarial frameworks, which can lead to both under- and over-protection. For instance, such models often assume that an adversary attacks a protected record exactly once. We introduce a principled approach to explicitly model the attack process as a series of steps. Specically, we engineer a factored Markov decision process (FMDP) to optimally plan an attack from the adversary's perspective and assess the privacy risk accordingly. The FMDP captures the uncertainty in the adversary's belief (e.g., the number of identied individuals that match the de-identified data) and enables the analysis of various real world deterrence mechanisms beyond a traditional protection model, such as a penalty for committing an attack. We present an algorithm to solve the FMDP and illustrate its efficiency by simulating an attack on publicly accessible U.S. census records against a real identied resource of over 500,000 individuals in a voter registry. Our results demonstrate that while traditional privacy models commonly expect an adversary to attack exactly once per record, an optimal attack in our model may involve exploiting none, one, or more indiviuals in the pool of candidates, depending on context.
Stackelberg game models of security have received much attention, with a number of approaches for
computing Stackelberg equilibria in games with a single defender protecting a collection of targets. In contrast, multi-defender security games have received significantly less attention, particularly when each defender protects more than a single target. We fill this gap by considering a multi-defender security game, with a focus on theoretical characterizations of equilibria and the price of anarchy. We present the analysis of three models of increasing generality, two in which each defender protects multiple targets. In all models, we find that the defenders often have the incentive to over protect the targets, at times significantly. Additionally, in the simpler models, we find that the price of anarchy is unbounded, linearly increasing both in the number of defenders and the number of targets per defender. Surprisingly, when we consider a more general model, this results obtains only in a “corner” case in the space of parameters; in most cases, however, the price of anarchy converges to a constant when the number of defenders increases.
ABSTRACT: We consider an onlinse optimization problem on a compact subset S ⊂ Rn (not necessarily convex), in which a decision maker chooses, at each iteration t, a probability distribution xover S, and seeks to minimize a cumulative expected loss, 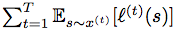 , where ℓ(t) is a Lipschitz loss function revealed at the end of iteration t. Building on previous work, we propose a generalized Hedge algorithm and show a
, where ℓ(t) is a Lipschitz loss function revealed at the end of iteration t. Building on previous work, we propose a generalized Hedge algorithm and show a 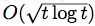 bound on the regret when the losses are uniformly Lipschitz and S is uniformly fat (a weaker condition than convexity). Finally, we propose a generalization to the dual averaging method on the set of Lebesgue-continuous distributions over S.
bound on the regret when the losses are uniformly Lipschitz and S is uniformly fat (a weaker condition than convexity). Finally, we propose a generalization to the dual averaging method on the set of Lebesgue-continuous distributions over S.
We examine the problem of aggregating the results of multiple anti-virus (AV) vendors' detectors into a single authoritative ground-truth label for every binary. To do so, we adapt a well-known generative Bayesian model that postulates the existence of a hidden ground truth upon which the AV labels depend. We use training based on Expectation Maximization for this fully unsupervised technique. We evaluate our method using 279,327 distinct binaries from VirusTotal, each of which appeared for the rst time between January 2012 and June 2014.
Our evaluation shows that our statistical model is consistently more accurate at predicting the future-derived ground truth than all unweighted rules of the form \k out of n" AV detections. In addition, we evaluate the scenario where partial ground truth is available for model building. We train a logistic regression predictor on the partial label information. Our results show that as few as a 100 randomly selected training instances with ground truth are enough to achieve 80% true positive rate for 0.1% false positive rate. In comparison, the best unweighted threshold rule provides only 60% true positive rate at the same false positive rate.
Computing a user-task assignment for a workflow coming with probabilistic user availability provides a measure of completion rate or resiliency. To a workflow designer this indicates a risk of failure, espe- cially useful for workflows which cannot be changed due to rigid security constraints. Furthermore, resiliency can help outline a mitigation strategy which states actions that can be performed to avoid workflow failures. A workflow with choice may have many different resiliency values, one for each of its execution paths. This makes understanding failure risk and mitigation requirements much more complex. We introduce resiliency variance, a new analysis metric for workflows which indicates volatility from the resiliency average. We suggest this metric can help determine the risk taken on by implementing a given workflow with choice. For instance, high average resiliency and low variance would suggest a low risk of workflow failure.
Workflows are complex operational processes that include security constraints restricting which users can perform which tasks. An improper user-task assignment may prevent the completion of the work- flow, and deciding such an assignment at runtime is known to be complex, especially when considering user unavailability (known as the resiliency problem). Therefore, design tools are required that allow fast evaluation of workflow resiliency. In this paper, we propose a methodology for work- flow designers to assess the impact of the security policy on computing the resiliency of a workflow. Our approach relies on encoding a work- flow into the probabilistic model-checker PRISM, allowing its resiliency to be evaluated by solving a Markov Decision Process. We observe and illustrate that adding or removing some constraints has a clear impact on the resiliency computation time, and we compute the set of security constraints that can be artificially added to a security policy in order to reduce the computation time while maintaining the resiliency.
Workflows capture complex operational processes and include security constraints limiting which users can perform which tasks. An improper security policy may prevent cer- tain tasks being assigned and may force a policy violation. Deciding whether a valid user-task assignment exists for a given policy is known to be extremely complex, especially when considering user unavailability (known as the resiliency problem). Therefore tools are required that allow automatic evaluation of workflow resiliency. Modelling well defined workflows is fairly straightforward, however user availabil- ity can be modelled in multiple ways for the same workflow. Correct choice of model is a complex yet necessary concern as it has a major impact on the calculated resiliency. We de- scribe a number of user availability models and their encod- ing in the model checker PRISM, used to evaluate resiliency. We also show how model choice can affect resiliency computation in terms of its value, memory and CPU time.
Best Poster Award, ACM SIGCOMM Conference on Principles of Advanced Discrete Simulation, London, UK, June 10-12, 2015.
The advancement of software-defined networking (SDN) technology is highly dependent on the successful transformations from in-house research ideas to real-life products. To enable such transformations, a testbed offering scalable and high fidelity networking environment for testing and evaluating new/existing designs is extremely valuable. Mininet, the most popular SDN emulator by far, is designed to achieve both accuracy and scalability by running unmodified code of network applications in lightweight Linux Containers. How- ever, Mininet cannot guarantee performance fidelity under high workloads, in particular when the number of concurrent active events is more than the number of parallel cores. In this project, we develop a lightweight virtual time system in Linux container and integrate the system with Mininet, so that all the containers have their own virtual clocks rather than using the physical system clock which reflects the se- rialized execution of multiple containers. With the notion of virtual time, all the containers perceive virtual time as if they run independently and concurrently. As a result, inter- actions between the containers and the physical system are artificially scaled, making a network appear to be ten times faster from the viewpoint of applications within the contain- ers than it actually is. We also design an adaptive virtual time scheduling subsystem in Mininet, which is responsible to balance the experiment speed and fidelity. Experimen- tal results demonstrate that embedding virtual time into Mininet significantly enhances its performance fidelity, and therefore, results in a useful platform for the SDN community to conduct scalable experiments with high fidelity.
Fat-tree topologies have been widely adopted as the communication network in data centers in the past decade. Nowa- days, high-performance computing (HPC) system designers are considering using fat-tree as the interconnection network for the next generation supercomputers. For extreme-scale computing systems like the data centers and supercomput- ers, the performance is highly dependent on the intercon- nection networks. In this paper, we present FatTreeSim, a PDES-based toolkit consisting of a highly scalable fat-tree network model, with the goal of better understanding the de- sign constraints of fat-tree networking architectures in data centers and HPC systems, as well as evaluating the applica- tions running on top of the network. FatTreeSim is designed to model and simulate large-scale fat-tree networks up to millions of nodes with protocol-level fidelity. We have con- ducted extensive experiments to validate and demonstrate the accuracy, scalability and usability of FatTreeSim. On Argonne Leadership Computing Facility’s Blue Gene/Q sys- tem, Mira, FatTreeSim is capable of achieving a peak event rate of 305 M/s for a 524,288-node fat-tree model with a total of 567 billion committed events. The strong scaling experiments use up to 32,768 cores and show a near linear scalability. Comparing with a small-scale physical system in Emulab, FatTreeSim can accurately model the latency in the same fat-tree network with less than 10% error rate for most cases. Finally, we demonstrate FatTreeSim’s usability through a case study in which FatTreeSim serves as the net- work module of the YARNsim system, and the error rates for all test cases are less than 13.7%.
Best Paper Award
Realistic and scalable testing systems are critical to evaluate network applications and protocols to ensure successful real system deployments. Container-based network emula- tion is attractive because of the combination of many desired features of network simulators and physical testbeds . The success of Mininet, a popular software- defined networking (SDN) emulation testbed, demonstrates the value of such approach that we can execute unmodified binary code on a large- scale emulated network with lightweight OS-level vir- tualization techniques. However, an ordinary network em- ulator uses the system clock across all the containers even if a container is not being scheduled to run. This leads to the issue of temporal fidelity, especially with high workloads. Virtual time sheds the light on the issue of preserving tem- poral fidelity for large-scale emulation. The key insight is to trade time with system resources via precisely scaling the time of interactions between containers and physical devices by a factor of n, hence, making an emulated network ap- pear to be n times faster from the viewpoints of applications in the container. In this paper, we develop a lightweight Linux-container-based virtual time system and integrate the system to Mininet for fidelity and scalability enhancement. We also design an adaptive time dilation scheduling mod- ule for balancing speed and accuracy. Experimental results demonstrate that (1) with virtual time, Mininet is able to accurately emulate a network n times larger in scale, where n is the scaling factor, with the system behaviors closely match data obtained from a physical testbed; and (2) with the adaptive time dilation scheduling, we reduce the running time by 46% with little accuracy loss. Finally, we present a case study using the virtual-time-enabled Mininet to evalu- ate the limitations of equal-cost multi-path (ECMP) routing in a data center network.
It is critical to ensure that network policy remains consistent during state transitions. However, existing techniques impose a high cost in update delay, and/or FIB space. We propose the Customizable Consistency Generator (CCG), a fast and generic framework to support customizable consistency policies during network updates. CCG effectively reduces the task of synthesizing an update plan under the constraint of a given consistency policy to a verification problem, by checking whether an update can safely be installed in the network at a particular time, and greedily processing network state transitions to heuristically minimize transition delay. We show a large class of consistency policies are guaranteed by this greedy heuristic alone; in addition, CCG makes judicious use of existing heavier-weight network update mechanisms to provide guarantees when necessary. As such, CCG nearly achieves the “best of both worlds”: the efficiency of simply passing through updates in most cases, with the consistency guarantees of more heavyweight techniques. Mininet and physical testbed evaluations demonstrate CCG’s capability to achieve various types of consistency, such as path and bandwidth properties, with zero switch memory overhead and up to a 3× delay reduction compared to previous solutions.