

 Biblio
Biblio
We present DeepPicar, a low-cost deep neural network based autonomous car platform. DeepPicar is a small scale replication of a real self-driving car called DAVE-2 by NVIDIA. DAVE-2 uses a deep convolutional neural network (CNN), which takes images from a front-facing camera as input and produces car steering angles as output. DeepPicar uses the same network architecture—9 layers, 27 million connections and 250K parameters—and can drive itself in real-time using a web camera and a Raspberry Pi 3 quad-core platform. Using DeepPicar, we analyze the Pi 3’s computing capabilities to support end-to-end deep learning based real-time control of autonomous vehicles. We also systematically compare other contemporary embedded computing platforms using the DeepPicar’s CNN-based real-time control workload. We find that all tested platforms, including the Pi 3, are capable of supporting the CNN-based real-time control, from 20 Hz up to 100 Hz, depending on hardware platform. However, we find that shared resource contention remains an important issue that must be considered in applying CNN models on shared memory based embedded computing platforms; we observe up to 11.6X execution time increase in the CNN based control loop due to shared resource contention. To protect the CNN workload, we also evaluate state-of-the-art cache partitioning and memory bandwidth throttling techniques on the Pi 3. We find that cache partitioning is ineffective, while memory bandwidth throttling is an effective solution.
Coverage-based Greybox Fuzzing (CGF) is a random testing approach that requires no program analysis. A new test is generated by slightly mutating a seed input. If the test exercises a new and interesting path, it is added to the set of seeds; otherwise, it is discarded. We observe that most tests exercise the same few "high-frequency" paths and develop strategies to explore significantly more paths with the same number of tests by gravitating towards low-frequency paths. We explain the challenges and opportunities of CGF using a Markov chain model which specifies the probability that fuzzing the seed that exercises path i generates an input that exercises path j. Each state (i.e., seed) has an energy that specifies the number of inputs to be generated from that seed. We show that CGF is considerably more efficient if energy is inversely proportional to the density of the stationary distribution and increases monotonically every time that seed is chosen. Energy is controlled with a power schedule. We implemented the exponential schedule by extending AFL. In 24 hours, AFLFAST exposes 3 previously unreported CVEs that are not exposed by AFL and exposes 6 previously unreported CVEs 7x faster than AFL. AFLFAST produces at least an order of magnitude more unique crashes than AFL.
We propose a new voting scheme, BeleniosRF, that offers both receipt-freeness and end-to-end verifiability. It is receipt-free in a strong sense, meaning that even dishonest voters cannot prove how they voted. We provide a game-based definition of receipt-freeness for voting protocols with non-interactive ballot casting, which we name strong receipt-freeness (sRF). To our knowledge, sRF is the first game-based definition of receipt-freeness in the literature, and it has the merit of being particularly concise and simple. Built upon the Helios protocol, BeleniosRF inherits its simplicity and does not require any anti-coercion strategy from the voters. We implement BeleniosRF and show its feasibility on a number of platforms, including desktop computers and smartphones.
The emerging software-defined networking (SDN) technology decouples the control plane from the data plane in a computer network with open and standardized interfaces, and hence opens up the network designers’ options and ability to innovate. The wide adoption of SDN in industry has motivated the development of large-scale, high-fidelity testbeds for evaluation of systems that incorporate SDN. In this article, we develop a framework to support OpenFlow-based SDN simulation and distributed emulation, by leveraging our prior work on a hybrid network testbed with a parallel network simulator and a virtual-machine-based emulation system. We show how to exploit typical SDN controller behaviors to handle performance issues caused by the centralized controller in parallel discrete-event simulation. In particular, we develop an asynchronous synchronization algorithm for passive SDN controllers and design a two-level architecture for active SDN controllers. We evaluate the system performance, showing good scalability. Finally, we present a case study, using the testbed, to evaluate network verification applications in an SDN-based data center network. CCS Concepts: Networks→Network simulations; Computing methodologies→Simulation
This paper focuses on the optimal sensor placement problem for the identification of pipe failure locations in large-scale urban water systems. The problem involves selecting the minimum number of sensors such that every pipe failure can be uniquely localized. This problem can be viewed as a minimum test cover (MTC) problem, which is NP-hard. We consider two approaches to obtain approximate solutions to this problem. In the first approach, we transform the MTC problem to a minimum set cover (MSC) problem and use the greedy algorithm that exploits the submodularity property of the MSC problem to compute the solution to the MTC problem. In the second approach, we develop a new \textit{augmented greedy} algorithm for solving the MTC problem. This approach does not require the transformation of the MTC to MSC. Our augmented greedy algorithm provides in a significant computational improvement while guaranteeing the same approximation ratio as the first approach. We propose several metrics to evaluate the performance of the sensor placement designs. Finally, we present detailed computational experiments for a number of real water distribution networks.
The malware detection arms race involves constant change: malware changes to evade detection and labels change as detection mechanisms react. Recognizing that malware changes over time, prior work has enforced temporally consistent samples by requiring that training binaries predate evaluation binaries. We present temporally consistent labels, requiring that training labels also predate evaluation binaries since training labels collected after evaluation binaries constitute label knowledge from the future. Using a dataset containing 1.1 million binaries from over 2.5 years, we show that enforcing temporal label consistency decreases detection from 91% to 72% at a 0.5% false positive rate compared to temporal samples alone.
The impact of temporal labeling demonstrates the potential of improved labels to increase detection results. Hence, we present a detector capable of selecting binaries for submission to an expert labeler for review. At a 0.5% false positive rate, our detector achieves a 72% true positive rate without an expert, which increases to 77% and 89% with 10 and 80 expert queries daily, respectively. Additionally, we detect 42% of malicious binaries initially undetected by all 32 antivirus vendors from VirusTotal used in our evaluation. For evaluation at scale, we simulate the human expert labeler and show that our approach is robust against expert labeling errors. Our novel contributions include a scalable malware detector integrating manual review with machine learning and the examination of temporal label consistency
As smart meters continue to be deployed around the world collecting unprecedented levels of fine-grained data about consumers, we need to find mechanisms that are fair to both, (1) the electric utility who needs the data to improve their operations, and (2) the consumer who has a valuation of privacy but at the same time benefits from sharing consumption data. In this paper we address this problem by proposing privacy contracts between electric utilities and consumers with the goal of maximizing the social welfare of both. Our mathematical model designs an optimization problem between a population of users that have different valuations on privacy and the costs of operation by the utility. We then show how contracts can change depending on the probability of a privacy breach. This line of research can help inform not only current but also future smart meter collection practices.
As our ground transportation infrastructure modernizes, the large amount of data being measured, transmitted, and stored motivates an analysis of the privacy aspect of these emerging cyber-physical technologies. In this paper, we consider privacy in the routing game, where the origins and destinations of drivers are considered private. This is motivated by the fact that this spatiotemporal information can easily be used as the basis for inferences for a person's activities. More specifically, we consider the differential privacy of the mapping from the amount of flow for each origin-destination pair to the traffic flow measurements on each link of a traffic network. We use a stochastic online learning framework for the population dynamics, which is known to converge to the Nash equilibrium of the routing game. We analyze the sensitivity of this process and provide theoretical guarantees on the convergence rates as well as differential privacy values for these models. We confirm these with simulations on a small example.
This paper considers a 2-player strategic game for network routing under link disruptions. Player 1 (defender) routes flow through a network to maximize her value of effective flow while facing transportation costs. Player 2 (attacker) simultaneously disrupts one or more links to maximize her value of lost flow but also faces cost of disrupting links. This game is strategically equivalent to a zero-sum game. Linear programming duality and the max-flow min-cut theorem are applied to obtain properties that are satisfied in any mixed Nash equilibrium. In any equilibrium, both players achieve identical payoffs. While the defender's expected transportation cost decreases in attacker's marginal value of lost flow, the attacker's expected cost of attack increases in defender's marginal value of effective flow. Interestingly, the expected amount of effective flow decreases in both these parameters. These results can be viewed as a generalization of the classical max-flow with minimum transportation cost problem to adversarial environments.
In order to be resilient to attacks, a cyber-physical system (CPS) must be able to detect attacks before they can cause significant damage. To achieve this, \emph{intrusion detection systems} (IDS) may be deployed, which can detect attacks and alert human operators, who can then intervene. However, the resource-constrained nature of many CPS poses a challenge, since reliable IDS can be computationally expensive. Consequently, computational nodes may not be able to perform intrusion detection continuously, which means that we have to devise a schedule for performing intrusion detection. While a uniformly random schedule may be optimal in a purely cyber system, an optimal schedule for protecting CPS must also take into account the physical properties of the system, since the set of adversarial actions and their consequences depend on the physical systems. Here, in the context of water distribution networks, we study IDS scheduling problems in two settings and under the constraints on the available battery supplies. In the first problem, the objective is to design, for a given duration of time $T$, scheduling schemes for IDS so that the probability of detecting an attack is maximized within that duration. We propose efficient heuristic algorithms for this general problem and evaluate them on various networks. In the second problem, our objective is to design scheduling schemes for IDS so that the overall lifetime of the network is maximized while ensuring that an intruder attack is always detected. Various strategies to deal with this problem are presented and evaluated for various networks.
This paper considers a 2-player strategic game for network routing under link disruptions. Player 1 (defender) routes flow through a network to maximize her value of effective flow while facing transportation costs. Player 2 (attacker) simultaneously disrupts one or more links to maximize her value of lost flow but also faces cost of disrupting links. This game is strategically equivalent to a zero-sum game. Linear programming duality and the max-flow min-cut theorem are applied to obtain properties that are satisfied in any mixed Nash equilibrium. In any equilibrium, both players achieve identical payoffs. While the defender's expected transportation cost decreases in attacker's marginal value of lost flow, the attacker's expected cost of attack increases in defender's marginal value of effective flow. Interestingly, the expected amount of effective flow decreases in both these parameters. These results can be viewed as a generalization of the classical max-flow with minimum transportation cost problem to adversarial environments.
Despite decades of effort to combat spam, unwanted and even malicious emails, such as phish which aim to deceive recipients into disclosing sensitive information, still routinely find their way into one’s mailbox. To be sure, email filters manage to stop a large fraction of spam emails from ever reaching users, but spammers and phishers have mastered the art of filter evasion, or manipulating the content of email messages to avoid being filtered. We present a unique behavioral experiment designed to study email filter evasion. Our experiment is framed in somewhat broader terms: given the widespread use of machine learning methods for distinguishing spam and non-spam, we investigate how human subjects manipulate a spam template to evade a classification-based filter. We find that adding a small amount of noise to a filter significantly reduces the ability of subjects to evade it, observing that noise does not merely have a short-term impact, but also degrades evasion performance in the longer term. Moreover, we find that greater coverage of an email template by the classifier (filter) features significantly increases the difficulty of evading it. This observation suggests that aggressive feature reduction—a common practice in applied machine learning—can actually facilitate evasion. In addition to the descriptive analysis of behavior, we develop a synthetic model of human evasion behavior which closely matches observed behavior and effectively replicates experimental findings in simulation.
Monitoring large areas using sensors is fundamental in a number of applications, including electric power grid, traffic networks, and sensor-based pollution control systems. However, the number of sensors that can be deployed is often limited by financial or technological constraints. This problem is further complicated by the presence of strategic adversaries, who may disable some of the deployed sensors in order to impair the operator's ability to make predictions. Assuming that the operator employs a Gaussian-process-based regression model, we formulate the problem of attack-resilient sensor placement as the problem of selecting a subset from a set of possible observations, with the goal of minimizing the uncertainty of predictions. We show that both finding an optimal resilient subset and finding an optimal attack against a given subset are NP-hard problems. Since both the design and the attack problems are computationally complex, we propose efficient heuristic algorithms for solving them and present theoretical approximability results. Finally, we show that the proposed algorithms perform exceptionally well in practice using numerical results based on real-world datasets.
Spear-phishing attacks pose a serious threat to sensitive computer systems, since they sidestep technical security mechanisms by exploiting the carelessness of authorized users. A common way to mitigate such attacks is to use e-mail filters which block e-mails with a maliciousness score above a chosen threshold. Optimal choice of such a threshold involves a tradeoff between the risk from delivered malicious emails and the cost of blocking benign traffic. A further complicating factor is the strategic nature of an attacker, who may selectively target users offering the best value in terms of likelihood of success and resulting access privileges. Previous work on strategic threshold-selection considered a single organization choosing thresholds for all users. In reality, many organizations are potential targets of such attacks, and their incentives need not be well aligned. We therefore consider the problem of strategic threshold-selection by a collection of independent self-interested users. We characterize both Stackelberg multi-defender equilibria, corresponding to short-term strategic dynamics, as well as Nash equilibria of the simultaneous game between all users and the attacker, modeling long-term dynamics, and exhibit a polynomial-time algorithm for computing short-term (Stackelberg) equilibria. We find that while Stackelberg multi-defender equilibrium need not exist, Nash equilibrium always exists, and remarkably, both equilibria are unique and socially optimal.
Cyber-Physical Systems (CPS) are systems with seamless integration of physical, computational and networking components. These systems can potentially have an impact on the physical components, hence it is critical to safeguard them against a wide range of attacks. In this paper, it is argued that an effective approach to achieve this goal is to systematically identify the potential threats at the design phase of building such systems, commonly achieved via threat modeling. In this context, a tool to perform systematic analysis of threat modeling for CPS is proposed. A real-world wireless railway temperature monitoring system is used as a case study to validate the proposed approach. The threats identified in the system are subsequently mitigated using National Institute of Standards and Technology (NIST) standards.
Stackelberg security games have been widely deployed in recent years to schedule security resources. An assumption in most existing security game models is that one security resource assigned to a target only protects that target. However, in many important real-world security scenarios, when a resource is assigned to a target, it exhibits protection externalities: that is, it also protects other "neighbouring" targets. We investigate such Security Games with Protection Externalities (SPEs). First, we demonstrate that computing a strong Stackelberg equilibrium for an SPE is NP-hard, in contrast with traditional Stackelberg security games which can be solved in polynomial time. On the positive side, we propose a novel column generation based approach—CLASPE—to solve SPEs. CLASPE features the following novelties: 1) a novel mixed-integer linear programming formulation for the slave problem; 2) an extended greedy approach with a constant-factor approximation ratio to speed up the slave problem; and 3) a linear-scale linear programming that efficiently calculates the upper bounds of target-defined subproblems for pruning. Our experimental evaluation demonstrates that CLASPE enable us to scale to realistic-sized SPE problem instances.
Design-time analysis and verification of distributed real-time embedded systems necessitates the modeling of the time-varying performance of the network and comparing that to application requirements. Earlier work has shown how to build a system network model that abstracted away the network's physical medium and protocols which govern its access and multiplexing. In this work we show how to apply a network medium channel access protocol, such as Time-Division Multiple Access (TDMA), to our network analysis methods and use the results to show that the abstracted model without the explicit model of the protocol is valid.
Assuring communication integrity is a central problem in security. However, overhead costs associated with cryptographic primitives used towards this end introduce significant practical implementation challenges for resource-bounded systems, such as cyber-physical systems. For example, many control systems are built on legacy components which are computationally limited but have strict timing constraints. If integrity protection is a binary decision, it may simply be infeasible to introduce into such systems; without it, however, an adversary can forge malicious messages, which can cause signi cant physical or financial harm. We propose a formal game-theoretic framework for optimal stochastic message authentication, providing provable integrity guarantees for resource-bounded systems based on an existing MAC scheme. We use our framework to investigate attacker deterrence, as well as optimal design of stochastic message authentication schemes when deterrence is impossible. Finally, we provide experimental results on the computational performance of our framework in practice.
Cheap ubiquitous computing enables the collectionof massive amounts of personal data in a wide variety of domains.Many organizations aim to share such data while obscuring fea-tures that could disclose identities or other sensitive information.Much of the data now collected exhibits weak structure (e.g.,natural language text) and machine learning approaches havebeen developed to identify and remove sensitive entities in suchdata. Learning-based approaches are never perfect and relyingupon them to sanitize data can leak sensitive information as aconsequence. However, a small amount of risk is permissiblein practice, and, thus, our goal is to balance the value ofdata published and the risk of an adversary discovering leakedsensitive information. We model data sanitization as a gamebetween 1) a publisher who chooses a set of classifiers to applyto data and publishes only instances predicted to be non-sensitiveand 2) an attacker who combines machine learning and manualinspection to uncover leaked sensitive entities (e.g., personal names). We introduce an iterative greedy algorithm for thepublisher that provably executes no more than a linear numberof iterations, and ensures a low utility for a resource-limitedadversary. Moreover, using several real world natural languagecorpora, we illustrate that our greedy algorithm leaves virtuallyno automatically identifiable sensitive instances for a state-of-the-art learning algorithm, while sharing over 93% of the original data, and completes after at most 5 iterations.
Starting with the seminal work by Kempe et al., a broad variety of problems, such as targeted marketing and the spread of viruses and malware, have been modeled as selecting
a subset of nodes to maximize diffusion through a network. In
cyber-security applications, however, a key consideration largely ignored in this literature is stealth. In particular, an attacker often has a specific target in mind, but succeeds only if the target is reached (e.g., by malware) before the malicious payload is detected and corresponding countermeasures deployed. The dual side of this problem is deployment of a limited number of monitoring units, such as cyber-forensics specialists, so as to limit the likelihood of such targeted and stealthy diffusion processes reaching their intended targets. We investigate the problem of optimal monitoring of targeted stealthy diffusion processes, and show that a number of natural variants of this problem are NP-hard to approximate. On the positive side, we show that if stealthy diffusion starts from randomly selected nodes, the defender’s objective is submodular, and a fast greedy algorithm has provable approximation guarantees. In addition, we present approximation algorithms for the setting in which an attacker optimally responds to the placement of monitoring nodes by adaptively selecting the starting nodes for the diffusion process. Our experimental results show that the proposed algorithms are highly effective and scalable.
The quantity of personal data gathered by service providers via our daily activities continues to grow at a rapid pace. The sharing, and the subsequent analysis of, such data can support a wide range of activities, but concerns around privacy often prompt an organization to transform the data to meet certain protection models (e.g., k-anonymity or E-differential privacy). These models, however, are based on simplistic adversarial frameworks, which can lead to both under- and over-protection. For instance, such models often assume that an adversary attacks a protected record exactly once. We introduce a principled approach to explicitly model the attack process as a series of steps. Specically, we engineer a factored Markov decision process (FMDP) to optimally plan an attack from the adversary's perspective and assess the privacy risk accordingly. The FMDP captures the uncertainty in the adversary's belief (e.g., the number of identied individuals that match the de-identified data) and enables the analysis of various real world deterrence mechanisms beyond a traditional protection model, such as a penalty for committing an attack. We present an algorithm to solve the FMDP and illustrate its efficiency by simulating an attack on publicly accessible U.S. census records against a real identied resource of over 500,000 individuals in a voter registry. Our results demonstrate that while traditional privacy models commonly expect an adversary to attack exactly once per record, an optimal attack in our model may involve exploiting none, one, or more indiviuals in the pool of candidates, depending on context.
Stackelberg game models of security have received much attention, with a number of approaches for
computing Stackelberg equilibria in games with a single defender protecting a collection of targets. In contrast, multi-defender security games have received significantly less attention, particularly when each defender protects more than a single target. We fill this gap by considering a multi-defender security game, with a focus on theoretical characterizations of equilibria and the price of anarchy. We present the analysis of three models of increasing generality, two in which each defender protects multiple targets. In all models, we find that the defenders often have the incentive to over protect the targets, at times significantly. Additionally, in the simpler models, we find that the price of anarchy is unbounded, linearly increasing both in the number of defenders and the number of targets per defender. Surprisingly, when we consider a more general model, this results obtains only in a “corner” case in the space of parameters; in most cases, however, the price of anarchy converges to a constant when the number of defenders increases.
ABSTRACT: We consider an onlinse optimization problem on a compact subset S ⊂ Rn (not necessarily convex), in which a decision maker chooses, at each iteration t, a probability distribution xover S, and seeks to minimize a cumulative expected loss, 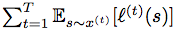 , where ℓ(t) is a Lipschitz loss function revealed at the end of iteration t. Building on previous work, we propose a generalized Hedge algorithm and show a
, where ℓ(t) is a Lipschitz loss function revealed at the end of iteration t. Building on previous work, we propose a generalized Hedge algorithm and show a 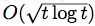 bound on the regret when the losses are uniformly Lipschitz and S is uniformly fat (a weaker condition than convexity). Finally, we propose a generalization to the dual averaging method on the set of Lebesgue-continuous distributions over S.
bound on the regret when the losses are uniformly Lipschitz and S is uniformly fat (a weaker condition than convexity). Finally, we propose a generalization to the dual averaging method on the set of Lebesgue-continuous distributions over S.