Data Driven Security Models and Analysis - October 2015
Data Driven Security Models and Analysis - October 2015
Public Audience
Purpose: To highlight project progress. Information is generally at a higher level which is accessible to the interested public. All information contained in the report (regions 1-3) is a Government Deliverable/CDRL.
PI(s): Ravi Iyer
Co-PI(s): Zbigniew Kalbarczyk and Adam Slagell
HARD PROBLEM(S) ADDRESSED
This refers to Hard Problems, released November 2012.
- Predictive security metrics - design, development, and validation
- Resilient architectures - in the end we want to use the metrics to achieve a measurable enhancement in system resiliency, i.e., the ability to withstand attacks
- Human behavior - data contain traces of the steps the attacker took, and hence inherently include some aspects of the human behavior (of both users and miscreants)
PUBLICATIONS
Papers published in this quarter as a result of this research. Include title, author(s), venue published/presented, and a short description or abstract. Identify which hard problem(s) the publication addressed. Papers that have not yet been published should be reported in region 2 below.
In preparation, see section 2.
ACCOMPLISHMENT HIGHLIGHTS
This quarter we have continued our work on: (i) building a security testbed that provides an execution platform for replaying security attacks in a controlled environment and (ii) demonstrating the value of Q-Learning by simulating a security game from a model derived based on security incident data.
1. Game Theory for Modeling Attacker / Defender Interaction
Game Theory with Learning for Cyber Security Monitoring. We performed a simulation-based experiment to evaluate the effectiveness of applying reinforcement learning for security games using the attack model derived from NCSA security incident data. (Game formulation and attack model are described in the previous report.)
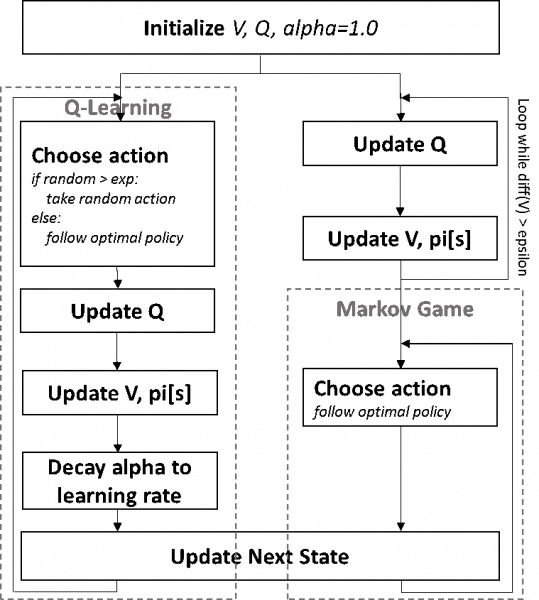
Figure 1: Simulator Flow Chart
Figure 1 depicts the structure of the simulator used in this experiment. It starts by initializing the value (V) and quality (Q) of states. Depending on the algorithm used for decision making, the simulator iterates over rounds of updating V, Q and pi. Note that the key difference between the traditional game theoretic approach (Markov Game) and the reinforcement learning approach (Q-Learning) is in the iteration of the game. While Markov Games goes over iterations of updating the optimal policy (pi) before the game and plays the game with a fixed optimal policy, Q-Learning updates the decision model (V and Q) along playing the game from a trial-and-error approach and derives the optimal policy from empirical results.
Using this simulator, we (i) compared the effectiveness of different algorithms on responding to suspicious opponent and (ii) studied the effect of different parameters for each algorithm. Comparing to the ideal (but unrealistic assumptions on full information about the opponent and full rationality of each player) case of deploying Markov Games, we confirm that Q-Learning algorithms show poor performance overall. (This was obvious as the Markov game is played with complete information about the opponent and full rationality of each players.) However, when played against less rational players (modeled by playing fully random or deploying Q-Learning), we found that Naive Q-Learning performs as good as Markov Games. Analyzing the performance on varying parameter (exploration rate, learning rate) settings, we determined that the defender, when deploying Q-Learning, only needs the rate of the player's decision deviating from the optimal strategy proposed by the algorithm to assure discovery of all possible actions. We observed that deviating from the defender's optimal policy does not benefit the defender unless the opponent is deviating from its own optimal strategy. Unlike the exploration rate, we concluded that the learning rate has no significant impact on the performance of the Q-Learning algorithm but only affects the time to convergence.
2. Data Driven Security Models and Analysis
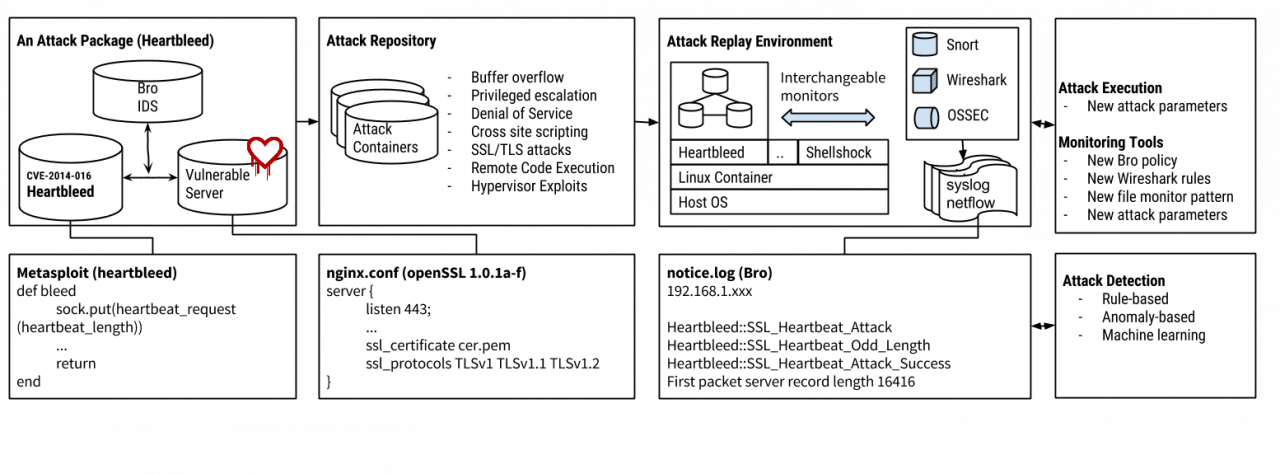
The current security testbed (see Figure 2) aims to be an End-to-End Attack Replay and Analysis system.
The testbed consists of a repository of attack containers and an isolated execution environment for the attacks based on Linux Containers. Each attack container contains a complete environment to run the attack and monitoring tools. Included attack artifacts are: executable exploits and vulnerable application software. The monitors include network and host monitors, such as Bro (network monitor) or Open Source Host-based Intrusion Detection System (OSSEC), to log events generated during the attack replay. The attack containers are implemented as Linux Containers, a lightweight virtualization technique.
The tesbed provides a template for developing and integrating with the testbed new attack scenarios. Also, we are working on implementing a hooking mechanisms for users to integrate and test their security policies using the testbed.
We have packaged twelve attacks to demonstrate simulation capability of the testbed in different scenarios (see Table 1). All of these attacks are ready for experiment. We plan to release our attack containers repository as open-source software to the community.
Table 1: List of attacks that can be replay in the testbed
| Name | Examples | Description |
|---|---|---|
| Privileged Escalation | Venom | Venom: Floppy driver buffer overflow |
| Denial of Service |
Slow POSTS DNS Reflections |
Slow POSTS: Send a very long input field over an extended period of time DNS Reflections: Amplify the number of network requests by exploiting UDP protocol in DNS queries |
| SSL/TLS |
POODLE Logiam Shellshock Heartbleeds |
POODLE: Decrypt cookies by slightly chaning HTTP records Logiam: Exploit weak Diffie-Hellman key exchange Shellshock: Inject arbitary code to shell Heartbleed: Read secret values in server memory |
| Remote Code Execution |
Buffer overflow SQL Injection |
Buffer overflow: Inject malicious input to overflow stack SQL Injection: Inject abitrary code to SQL queries |
| Web Applications | Cross Site Scripting (XSS) | XSS: Injector: Inject arbitary Javascript code to an URL |
| Man in the Middle |
PE Injector Malicious ISP |
PE Inector: Inject malicious shell code to Portable Exectable file on the wire Malicious ISP: Read communication among client and server |
Figure 2: Security testbed: workflow of creating replaying, and analyzing attack containers